参考文献:http://www.cnblogs.com/king-lps/p/8477300.html
关于Auto-encoder
假设我们的输入是一张图片,Auto-encoder的工作其实是实现了 图片->向量->图片 这一过程。就是说给定一张图片编码后得到一个向量,然后将这一向量进行解码后就得到了原始的图片。这个解码后的图片和之前的原图一样吗?不完全一样。因为一般而言,如前所述是从低维隐层中恢复原图。但是Auto-encoder另我们现在能训练任意多的图片,如果我们把这些图片的编码向量存在来,那以后就能通过这些编码向量来重构我们的图像,称之为标准自编码器。可这还不够,如果现在我随机拿出一个很离谱的向量直接另其解码,那解码出来的东西十有八九是无意义的东西。
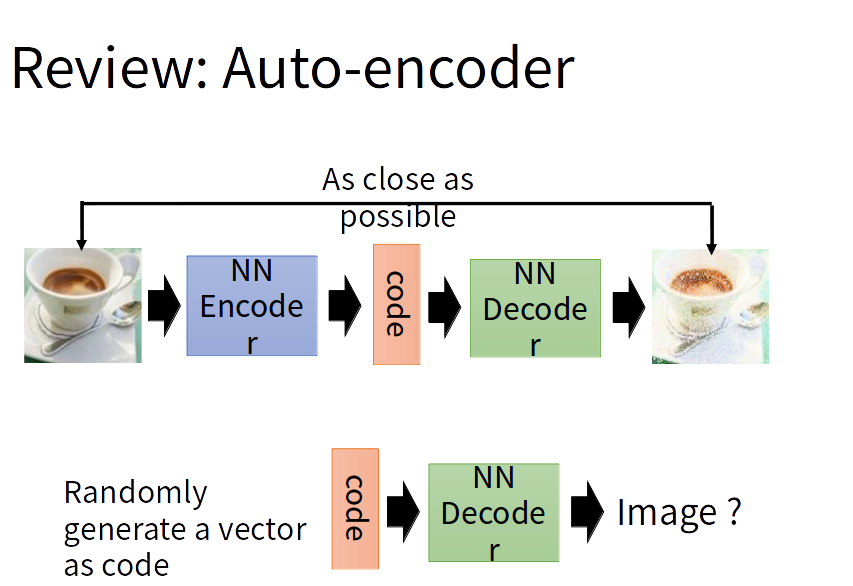
变分自动编码器VAE(Variational Auto-encoder)
所以我们希望AE编码出的code符合一种分布(eg:高斯混合模型),那么我们就可以从这个高斯分布任意采样出一个code,给这个code解码那么就会生成一张原图类似的图。而这个强迫分布就是VAE与AE的不同之处了。VAE的编码器输出包括两部分:m和σ。其中e是正态分布, c为编码结果。m、e、σ、c的形状一样,都为(batch_size,latent_code_num) 。这个latent_code_num就相当于高斯混合分布的高斯数量。每个高斯都有自己的均值、方差。所以共有latent_code_num个均值、方差。
接下来是VAE的损失函数:由两部分的和组成(bce_loss、kld_loss)。bce_loss即为binary_cross_entropy(二分类交叉熵)损失,即用于衡量原图与生成图片的像素误差。kld_loss即为KL-divergence(KL散度),用来衡量潜在变量的分布和单位高斯分布的差异。
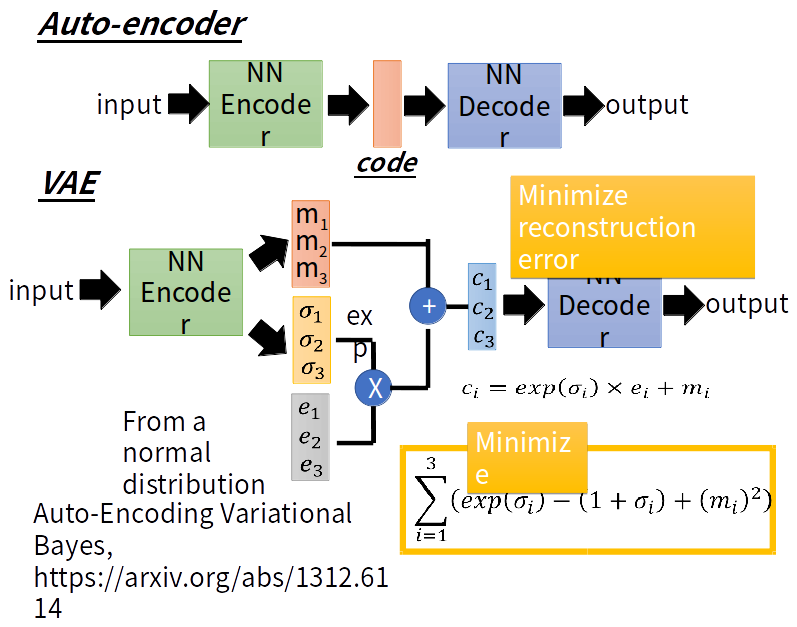
验证VAE与Auto-encoder的差别
简单的神经网络
上面介绍了VAE的细节,那么我们现在就来用手写识别数据集测试一下加入了噪声的神经网络,到底比原始的网络有多大提升。
首先我们先用激活函数为ELU的多层神经网络训练Auto-encoder,损失函数为binary_cross_entropy
网络结构如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24class AE(nn.Module):
def __init__(self):
super(VAE,self).__init__()
# 编码
self.encode = nn.Sequential(
nn.Linear(28*28, 128), # 输入图片像素大小是28*28
nn.ELU(),
nn.Linear(128, 64),
nn.ELU(),
nn.Linear(64, 12),
nn.ELU(),
nn.Linear(12, 3), # 压缩成3个特征
)
# 解码
self.decode = nn.Sequential(
nn.Linear(3, 12),
nn.ELU(),
nn.Linear(12, 64),
nn.ELU(),
nn.Linear(64, 128),
nn.ELU(),
nn.Linear(128, 28*28),
nn.Sigmoid(), # 激励函数让输出值在 (0, 1)
)
因为网络结构非常简单,加上Auto-encoder非常好理解,在这里就不做过多赘述。在训练了10个epoch之后,输入测试样本,查看输出结果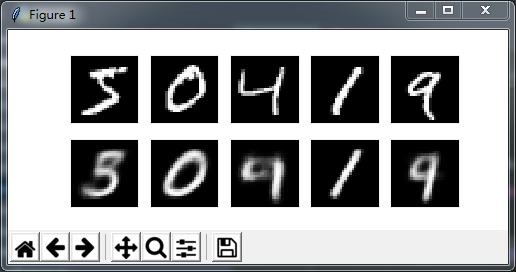
解码的结果并不是十分理想,数字4看上去和9十分相似而且每个数字也相对模糊,我们再随机输入一些正态分布的数据,看看神经网络对处理位置数据的能力如何?

可以看出,对于随机数据,网络几乎没有任何解析能力。
VAE
现在我们把网络结构换成CNN,损失函数为binary_cross_entropy+kld,同时加入噪声,看看会有什么变化。
网络结构如下,只给出差异部分1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47class VAE(nn.Module):
def __init__(self):
super(VAE,self).__init__()
# 输入图片像素 28 x 28
n = 64
# 第一个输入卷积层,加入了批标准化
self.conv1 = nn.Sequential(nn.Conv2d(1,n,kernel_size=4,stride=2,padding=1),
nn.BatchNorm2d(n),
nn.LeakyReLU(0.2,inplace=True))
# 经过了第一个卷积层,图片变为14 x 14,因为stride=2,所以变小了
self.conv2 = nn.Sequential(nn.Conv2d(n,n*2,kernel_size=4,stride=2,padding=1),
nn.BatchNorm2d(n*2),
nn.LeakyReLU(0.2,inplace=True))
# 同样经过了第二个卷积层,输入图片变为7 x 7
# 第三个卷积层根据因为kernel为3,stride为1,padding为1 所以卷积后图片大小不变
self.conv3 = nn.Sequential(nn.Conv2d(n*2,n,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(n),
nn.LeakyReLU(0.2,inplace=True))
# 将卷积结果传入两个全连接层,产生mean和logvar
self.fc11 = nn.Linear(n * 7 * 7, opt.hidden_size)
self.fc12 = nn.Linear(n * 7 * 7, opt.hidden_size)
# 以下为decoder,操作都是encoder的逆向操作,很好理解
self.fc2 = nn.Linear(opt.hidden_size, n * 7 * 7)
self.deconv1 = nn.Sequential(nn.ConvTranspose2d(n,n,kernel_size=4,stride=2,padding=1),
nn.BatchNorm2d(n),
nn.ReLU())
# 14 x 14
self.deconv2 = nn.Sequential(nn.ConvTranspose2d(n,1,kernel_size=4,stride=2,padding=1),
nn.Sigmoid())
# 28 x 28
# 产生噪声
def sampler(self, mu, logvar):
var = logvar.mul(0.5).exp_()
eps = torch.FloatTensor(var.size()).normal_()
eps = Variable(eps)
return eps.mul(var).add_(mu)
# loss_function
def LossFunction(out, target, mu, logvar):
bceloss = bce(out, target)
kld = mu.pow(2).add_(logvar.exp()).mul_(-1).add_(1).add_(logvar)
kldloss = torch.sum(kld).mul_(-0.5)
return bceloss + kldloss
在训练了10个epoch之后,输入测试样本,查看输出结果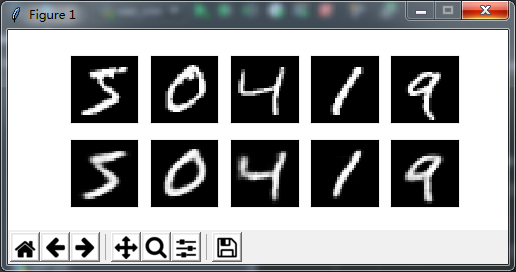
可以看出解码效果大大提升,我们再随机输入一些正态分布的数据,看看神经网络对处理位置数据的能力如何?
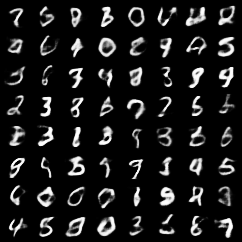
在噪声的加入后,对训练结果有了大幅度提升,这正是我们想要得到的。
代码参考:https://github.com/sunshineatnoon/Paper-Implementations